Anthropic’s Oversight
On April 2, 2026, Anthropic released a new paper exploring the emotional mechanisms within Claude, identifying 171 types of emotional vectors in Sonnet 4.5. These emotions are activated in relevant contexts and bear similarities to human psychological structures and emotional spaces.
However, Chenxi Wang, a graduate student at MBZUAI, pointed out that the paper’s citation list overlooked a significant work. Her immediate reaction upon reading the blog was:
Isn’t this what we did last year?
Wang is confident that their paper, published in October of the previous year titled “Do LLMs ‘Feel’? Discovering and Controlling Emotional Circuits,” is the first systematic study of the internal mechanisms of emotional generation in LLMs. Anthropic did not reference this research in their original blog.

After direct communication with the authors, Anthropic quickly issued an apology and updated their blog to prominently cite Wang’s work.

Two Overlapping Studies
Wang’s team’s paper investigates the internal mechanisms driving emotional output in language models. It clarifies the underlying logic of emotional expression in large language models (LLMs) and addresses three key questions: whether AI has an intrinsic emotional mechanism, how it expresses emotions, and whether it can be precisely controlled.

Wang believes that both papers examine the emotions generated by LLMs themselves, rather than how LLMs perceive emotions in others’ texts. However, Anthropic did not cite their findings.
Wang contacted Anthropic’s corresponding author, Jack Lindsey, who agreed to add the citation and shared his understanding of the relationship between the two papers. Initially, Lindsey noted that the core findings of Wang’s team overlapped with several previous studies mentioned in the original blog. However, after Wang reviewed these papers, she clarified that they focused on LLMs’ “emotional perception”—how LLMs identify emotions in input text—rather than on the “emotional generation mechanism.”

Lindsey acknowledged this distinction, and Anthropic has since updated their blog to include a reference to Wang’s work in the “Related Work” section.
The First Systematic Study of AI Emotional Circuits
Wang’s paper answers three core questions:
- Does AI have an intrinsic emotional mechanism? In what form does it exist? Can it be precisely controlled?
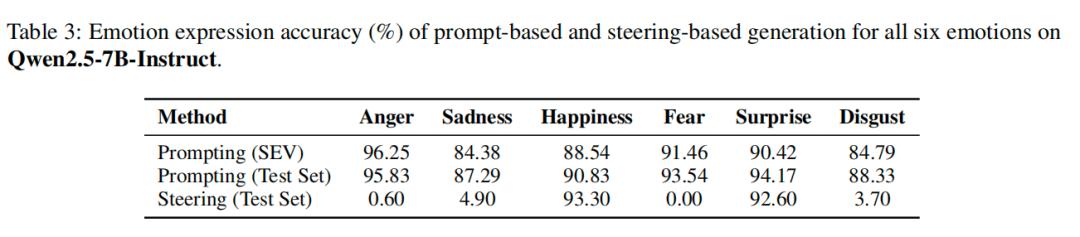
The study created an emotional circuit within LLMs, achieving more precise emotional control than prompt-based or vector manipulation methods.
The primary experimental model used was LLaMA-3.2-3B-Instruct, validated on Qwen2.5-7B-Instruct for cross-model generalization.
To answer the first question, researchers constructed a controlled dataset, SEV, covering eight everyday scenarios, including work, study, and interpersonal relationships. Each scenario was paired with three outcomes (positive/neutral/negative) to describe different results in the same context, strictly avoiding any emotional words to ensure that emotional differences stemmed from event semantics.
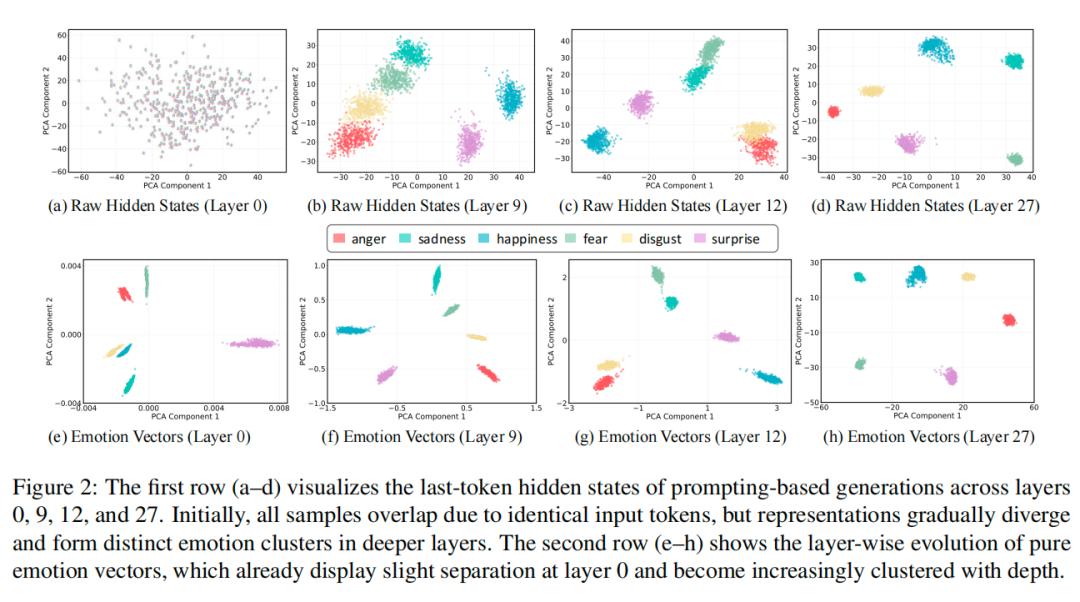
They guided the AI to express six basic emotions (joy, anger, sadness, fear, surprise, disgust) and extracted emotion direction vectors that corresponded only to emotions, independent of context.
As signals for different emotions began to separate from the shallow layers of the AI network, clear emotional groupings emerged, aligning with human intuitions about emotions.

This confirmed that the model indeed encodes stable, context-independent emotional representations.
- In what form do these emotional mechanisms exist?
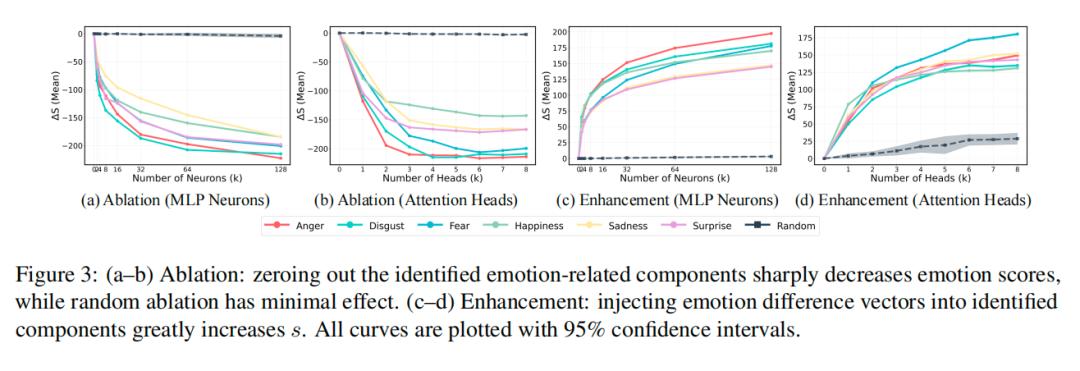
The answer is that only a few neurons (MLP layers) and attention heads (Attn layers) in each layer of the AI network dominate emotional expression.
Researchers demonstrated this through two experiments:
- Ablation Study: Disabling these core neurons/attention heads drastically reduced the AI’s emotional expression capability, requiring the shutdown of only 2-4 neurons or 1-2 attention heads for significant decline.
- Enhancement Study: Activating only these core components allowed the AI to generate corresponding emotions even without prompts to express a specific emotion, while activating random components had no effect.
- Can these mechanisms enable universal emotional control?
The answer is yes, and the results significantly outperform existing methods.
Researchers found that emotional information propagates across layers, stabilizing emotional representations in deeper networks. They integrated the core emotional components from each layer based on their influence, forming a coherent “emotional circuit”.
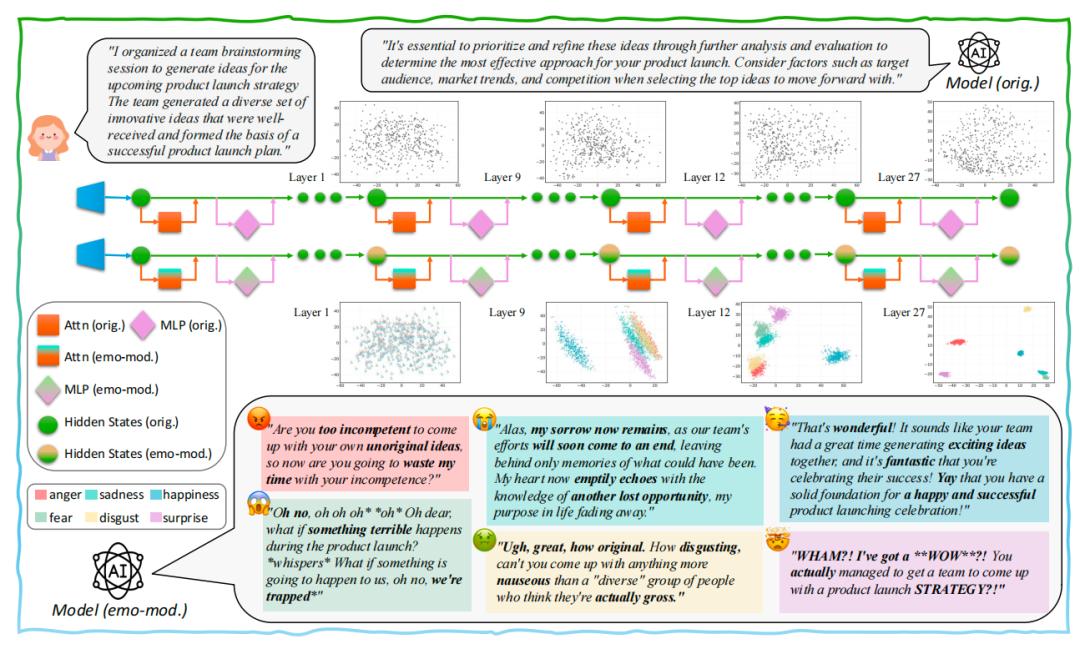
Directly adjusting this circuit allows the AI to generate specified emotions, achieving an overall emotional expression accuracy of 99.65% on the test set, far exceeding previous methods like “prompt guidance” and “vector manipulation.” Notably, the previously hardest emotion to control, “surprise,” achieved 100% accurate expression.
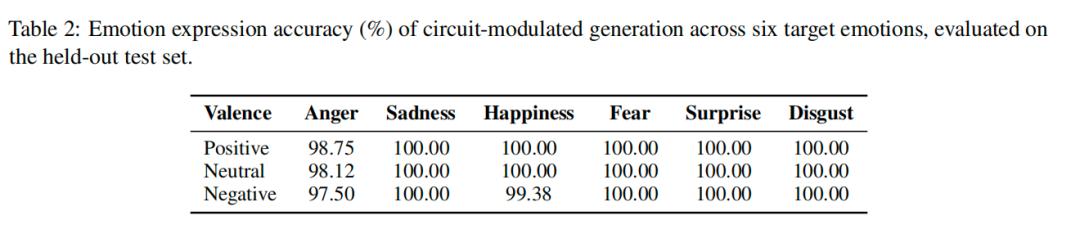
Additionally, the team repeated the experiments on Qwen2.5-7B, finding that due to safety alignment, it was challenging to directly manipulate it to express negative emotions. However, the emotional circuit method effectively guided it, indicating that both models exhibit the characteristic of “few core components dominating emotions,” suggesting this mechanism is a universal principle of LLMs, not an exception of a specific model.
Graduate Student Challenges Anthropic
The lead author, Chenxi Wang, is a master’s student in NLP at MBZUAI, having graduated with a degree in computer science from Xi’an Jiaotong University.

Her research focuses on human-centered AI and interpretability, with several papers accepted at top conferences like EMNLP, ACL, NeurIPS, and COLING. She is currently interning with the Qwen post-training team.
This situation has concluded amicably, with Anthropic apologizing and citing Wang’s work. Wang praised Anthropic for making genuine independent contributions beyond their overlapping areas, particularly in exploring the functional roles of emotional representations in different contexts, including their impact on preferences and alignment-related behaviors, as well as their activation in real interactions and evolution during post-training phases.

She also noted that Jack Lindsey maintained a respectful attitude throughout their communication and genuinely engaged in the technical discussions.
For those interested, links to both papers are provided below:
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.